Martin Gudgin
Корпорация Microsoft
Июль 2002
Перевод: sna
Применять к:
Расширяемый
язык разметки (Extensible Markup Language) (XML)
1.0
Спецификации пространств имен XML
Обзор: Рассматриваются наиболее важные типы информационных элементов
и их свойства, преобразование между свойствами Infoset
и формат сериализации, определенный спецификациями Расширяемого языка разметки
(XML) 1.0 и Пространствами имен в XML,
и взаимоотношения между Infoset и программными API XML.
Содержание
Введение
Корневой элемент
Элементы и атрибуты
Символы
Пространства имен
Сериализация
Преобразование в API
Заключение
Введение
Информационное множество XML (Infoset)
определяет модель данных для XML. Эта модель данных
является набором абстракций, которые детализируют свойства XML
деревьев. Эти абстракции обеспечивают общую точку зрения, исходя из которой
рассматриваются форматы сериализации, XML API и высокоуровневые спецификации, такие
как XPath, XSLT и XML Schema, как показано на Рисунке 1.
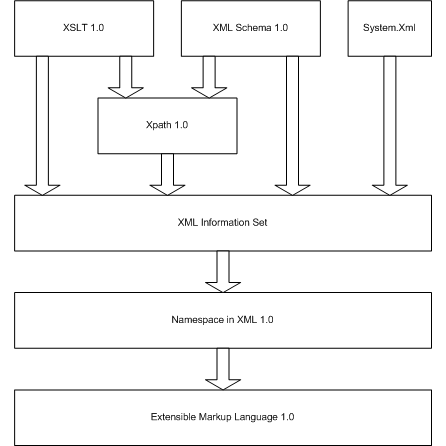
Рисунок 1. Абстракции XML
Очень важно иметь модель данных и ассоциированные абстракции; без них каждая
спецификация XML или API будут
вынуждены изобретать собственные. В этом есть два недостатка. Во-первых,
разработчикам XML придется учить новую модель данных
для каждой новой XML технологии; все они будут подобны,
но не идентичны. Во-вторых, не будет гарантии, что технологии XML
смогут работать вместе. Например, большинство XML стеков накладывают поддержку для XPath и XSLT на DOM API. Если бы каждая из этих
спецификаций имела бы разные модели данных, такое наслоение было бы
невозможным.
Кроме того, существование общей абстрактной модели данных делает возможным
строить знания о том, как использовать XML, не
зависящее или явно не связанное с определенной спецификацией XML
или API. Ценность такого независимого знания очевидна в
мире реляционных баз данных, где много усилий было
затрачено на то, чтобы решить как представить информацию в реляционных базах
данных в общем, а не только как использовать определенный продукт.
Абстракции в Infoset называются единицами информации.
Infoset определяет одиннадцать типов единиц информации.
Каждый имеет набор свойств. Некоторые из этих свойств являются простыми
значениями; некоторые из них – другими единицами информации или коллекциями
единиц информации. Последние свойства моделируют структурные взаимоотношения, в
то время как первые предоставляют информацию об отдельной единице информации.
Для непосредственной работы с единицами информации нет стандартного API. Вместо этого вы работаете с ними косвенно через другие XML технологии. Однако важно понимать, что описывают единицы
информации в Infoset и как они связаны друг с другом,
потому что это определяет границы того, как вы можете использовать XML. Например, единица информации Infoset
для элемента отображает, сколько у него потомков,
но не показывает, был ли элемент сериализован с начальным и конечным тэгами или
просто с пустым тэгом. На этом уровне вы знаете, что DOM,
XPath, XSLT или любая другая
технология обработки XML может обнаружить, что у
элемента нет потомков, но не то, был ли он сериализован с использованием одного
или двух тэгов.
В этой статье рассмотрены наиболее важные типы единиц информации и их
свойства. Полный список единиц информации и все их свойства приведены на
странице XML
Information Set W3C Web сайта. Статья также
рассматривает преобразования между свойствами Infoset и
форматом сериализации, определенным спецификациями Extensible Markup Language (XML) 1.0 (Second Edition) и Namespaces in XML. И наконец, статья касается взаимоотношений между Infoset и программными API XML.
Корневой элемент
Корневым элементом Infoset всегда является единица информации документ. Самое
важное свойство документа
- свойство [children], которое является
списком единиц информации, которые являются прямыми потомками документа. Ровно один из этих элементов
информации – это элемент документа. Это точно создает ограничение на то,
что у XML деревьев всегда
должен быть именно один элемент верхнего уровня. Этот элемент известен как элемент документа и
также присутствует в свойстве [document element] документа. Комментарии
и инструкции по обработке единиц информации могут также появиться в свойстве [children]. В том случае, когда единственным потомком документа является элемент
документа, свойства [children]
и [document element] имеют, фактически, одинаковые значения.
Это не значит, что без документа XML был бы
лесом, а не деревом, из-за возможности появления комментариев и инструкций к
обработке перед и после элемента документа. Деревом XML делает документ,
который в большой степени полностью абстрактен.
Элементы и атрибуты
Информационные множества XML преимущественно
образованы элементами и атрибутами. Первые могут использоваться
для создания структурированных или простых значений, в то время как последние
могут использоваться только для создания простых значений. Оба типа единиц
информации имеют несколько важных свойств. У элемента свойство [parent] содержит единицу информации, являющуюся родителем для элемента.
В случае элемента документа - это документ, а для всех
остальных элементов – это будет другой элемент. В обоих случаях свойство
[children] родителя будет
содержать элемент. На Рисунке 2 показаны элемент с родителем документ.
Обратите внимание, что структурные взаимоотношения двунаправленные.
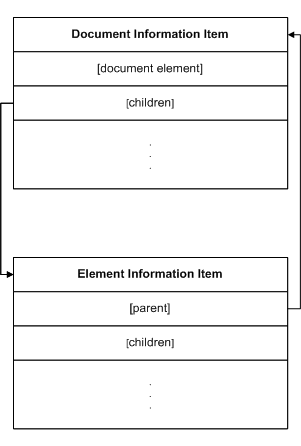
Рисунок 2. Документ и элемент
Элемент также имеет свойство [children],
которое, как и свойство [children] документа,
содержит всех прямых потомков элемента. Этими потомками могут быть
другие элементы, комментарии или инструкции
обработки или символы.
Элемент
имеет два связанных с именем свойства: [local name] и [namespace name].
Значением последнего является или URI пространства
имен, которому принадлежит элемент, или, если элемент не ассоциирован с
пространством имен, это свойство остается пустым. Значением свойства [local name]
является локальная часть имени элемента, ограниченная свойством [namespace name]. Вместе эти два
свойства образуют имя элемента. Два элемента с одинаковыми значениями
свойства [local name], но различными значениями свойства [namespace name],
считаются семантически различными.
Список атрибутов, ассоциированных с элементом, создается свойством [attributes]. Это свойство является неупорядоченным
списком атрибутов.
Такие единицы информации не считаются частью дерева непосредственно, поэтому
при проведение просмотра свойств [children] всех единиц информации, начиная с документа, не
встретится ни одного атрибута.
Атрибуты некоторые свойства используют
совместно с элементом.
Например, свойства [namespace name] и [local name] атрибута
интерпретируются точно так же, как и такие же свойства элемента. Однако другие аспекты атрибута
моделируются по-другому. Нет свойства [children];
вместо него атрибуты
имеют свойство [normalized value], содержащее простое значение атрибута. Также нет
свойства [parent]; вместо него есть
свойство [owner element], значением которого является элемент. На Рисунке 3 показан элемент и ассоциированный с ним атрибут.
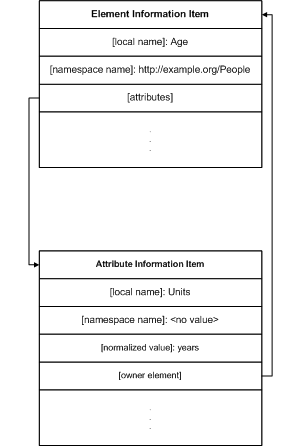
Рисунок 3. Элемент и ассоциированный с ним атрибут
Символы
Текстовое содержимое элемента
создается с использованием символов. Есть свойство [parent],
содержащее элемент, в свойстве [children] которой содержится символы.
Другое важное свойство – это свойство [character code], значением которого
является код символа ISO 10646, представляющий символы.
В Таблице 1 приведены несколько символов ISO 10646
вместе с соответствующими именами и кодами символов, а на Рисунке 4 показаны элементы с ассоциированными атрибутами и символами.
Таблица 1. Символы и коды
символов
|
Character
|
Имя
|
Код
|
|
a
|
Латинская маленькая буква A
|
0x0061
|
|
ã
|
Латинская маленькая буква A с тильдой
|
0x00E3
|
|
æ
|
Латинская маленькая буква Ae
|
0x00E6
|
|
|
Греческая маленькая буква Alpha
|
0x03B1
|
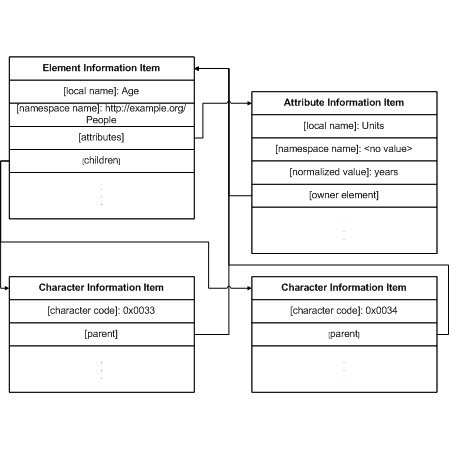
Рисунок 4. Элемент с ассоциированными атрибутом и символами
Пространства имен
Пространства имен используются для устранения неоднозначности в именах элементов
и атрибутов. Как обсуждалось ранее, имя каждого
элемента и атрибута состоит из двух частей. Когда часть имени
[namespace name] не пустая, говорят, что имя является составным, локальная часть определяется частью
пространства имен. Infoset создает пространства имен,
используя комбинацию пространства имен и атрибутов.
У каждого элемента есть свойство [in-scope
namespaces], содержащее ряд пространств
имен. У этих единиц информации есть два свойства: свойство [namespace name],
чьим значением является URI, и свойство [prefix], его значение – это префикс URI
пространства имен. Это преобразование префикса в имя пространства имен может
использоваться для определения принадлежности значений пространства имен в
дереве. Такие значения могут появиться как набор
символов элемента или как значение атрибутов.
Например, на Рисунке 5 показан атрибут, значение которого ссылается на
тип short в пространстве имен http://www.w3.org/2001/XMLSchema.
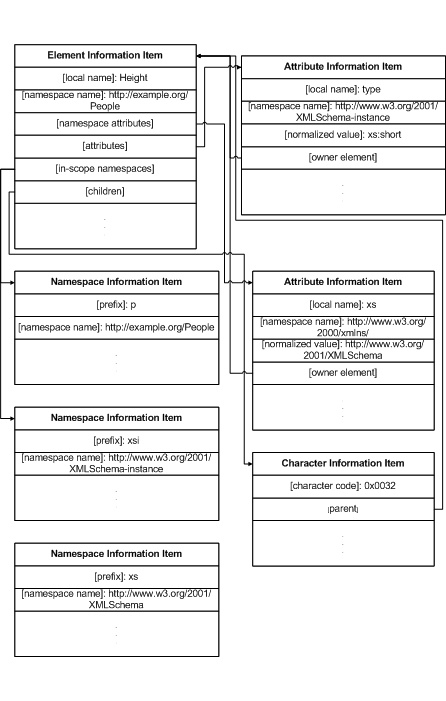
Рисунок 5. Интерпретация
значения атрибута как части пространства имен
У каждой элемента также есть
свойство[namespace attributes]. Это свойство является набором атрибутов. Для каждого атрибута в наборе
свойство [namespace name] всегда http://www.w3.org/2000/xmlns/. Часть [local name]
– это префикс, используемый при ссылании на элеметы
в этом пространстве имен. Атрибуты важны при сериализации и десериализации Infoset.
Сериализация
XML Infosets
обычно сериализуются по правилам, установленным XML 1.0
и Namespaces. Например, элементы сериализуются,
используя начальный и конечный тэги. Эти тэги содержат свойство [local name]
элемента вместе с префиксом, который преобразовывается в свойство [namespace name].
Ассоциированные атрибуты, включая
находящиеся в свойстве [namespace attributes],
сериализовываются как пары имя/значение в начальном тэге. Наиболее важны для сериализации атрибуты в
свойстве [namespace attributes]. Сериализация определяет диапазон для такого
префикса в описаниях URI. Код, приведенный ниже,
показывает элемент, в которой [local name] – Person
и [namespace name] - http://example.org/People.
Элемент имеет ассоциированный атрибут в свойстве [namespace attributes],
обеспечивая преобразование префикса p в имя пространства имен http://example.org/People. В свойстве [in-scope namespaces] есть соответствующее пространство имен.
Свойство [children] элемента
пустое. Если бы у элемента были бы потомки, каждый из них имел бы
пространство имен в свойстве [in-scope namespaces].
В XML допускается короткая,
сериализованная форма, в которой элементы имеет пустое свойство [children], как показано ниже:
Содержимое свойства [attributes]
сериализуется так же, как в свойстве [namespace attributes]. В следующем
коде показана сериализованная форма после добавления атрибута с id в свойстве [local name] и пустым свойством [namespace name],
с p1 в свойстве [normalized value].
Следующий код демонстрирует альтернативную сериализацию; обратите внимание,
что здесь больше пробелов и значения атрибутов заключены в кавычки, а не
в апострофы.
id="p1" />
Содержимое свойства [children] элемента
сериализуется между начальным и конечным тэгами. В него входят потомки элемента,
символы, а также комментарии и инструкции к обработке.
Символы сериализуются как коды символов независимо
от того, в какой кодировке написана сериализуемая форма, обычно это UTF-8 или UTF-16.
Кстати, если используется любая из этих кодировок, символы
просто переписываются, прямо как обе кодировки могут представить все ISO-10646.
Однако, если используется более ограниченная кодировка, скажем ISO-8859-1, тогда может понадобится сериализовать
определенные символы, используя ссылки на символы.
Ссылка на символ – это свойство [character code], сериализованное
как десятичное или шестнадцатеричное и разграниченное амперсандом и точкой с
запятой. В следующем коде показаны элемент с потомком. Этот элемент
сам имеет символы, некоторые из которых сериализуются как
ссылки на символы.
Martin Gudgin
Тот факт, что на уровне Infoset эти разнообразия сериализации невидимы, является преимуществом и высокоуровневых спецификаций, и
средств реализации API. Это дает возможность
сконцентрироваться на важных свойствах деревьев XML, а
не на деталях сериализации. Например, XSLT не надо
детализировать тот факт, что при написании XSLT
преобразований допускаются обе синтаксические формы элемента с пустым свойством
[children]. Точно так же API не надо указывать разделители
значениям атрибута. Побочным эффектом при рассмотрении вещей на уровне Infoset является то, что становится возможным работать с
вещами, которые не раскрывает Infoset. Например, нельзя написать выражение XPath , чтобы найти все атрибуты, разделителями в
которых выступают апострофы.
Интересно также отметить, что если бы использовалась другая сериализация, не
основанная на угловых скобках, но
обеспечивающая свойства Infoset, высокоуровневые
спецификации, такие как XSLT, все еще применялись бы, и
стандартные XML API все еще могли бы использоваться.
Преобразование в API
Infoset информирует разработчиков API
о том, какие свойства XML деревьев важны, а какие нет.
Такие XML API
как DOM, SAX и
XmlReader обеспечивают доступ к свойствам Infoset. Например, в
следующем коде показано извлечение свойств [namespace name] и [local name]
всех элементов в XML дереве с помощью XmlReader.
XmlReader xr =
new XmlTextReader ( "data.xml" );
while
(xr.Read())
{
if (
NodeType.Element == xt.NodeType )
{
Console.WriteLine ( "[local name]: {0}\n[namespace name]: {1}",
wr.LocalName, wr.NamespaceName );
}
}
Кроме работы с синтаксисом сериализации пространств имен XML
1.0 и XML, вполне возможно наслаивать XML API поверх источника данных, который не является XML. Microsoft® .NET включает XmlTextReader специально
для чтения сериализованных текстовых потоков XML, но также включает и XmlNodeReader
для чтения узлов в существующий DOM. Вы также можете написать собственные реализации XmlReader поверх других источников данных. Написаны
реализации для файловой системы, registry,
текстовых файлов с разделяющими запятыми и других форматов (см. The XML Files: Writing XML Providers for Microsoft .NET и
XmlCsvReader Implementation).
Потребители реализации XmlReader до сих пор работают
с данными как XML, даже несмотря на то, что базовые данные никогда не сериализуются с
использованием угловых скобок. Это очень мощная техника, потому что
высокоуровневые API, такие как XPath,
XSLT и XML Schema до сих пор могут применяться
к этим 'синтетическим' Infosets.
Философы всегда задавали
вопрос:”Если DOM дерево дает побеги, растет, стареет и
умирает и никогда не сериализуется с использованием угловых скобок, это XML?”. Так же они интересовались:”Если поток, вливающийся в XmlReader, полон
жизни, а затем высыхает на горячем солнце, но основные
данные не в угловых скобках, это XML?”. Ответ на эти
вопросы: “Это - XML Infoset”. И более того, т.к. все
больше многослойных спецификаций строятся на XML, чем больше вы думаете
и работаете в терминах Infosets, тем лучше. XML начинался как язык разметки, но эволюционировал в
платформу, сердцем которой является не XML 1.0, а XML Infoset.