| |
|
| |
Описание для автора не найдено
|
|
| |
|
|
| |
|
| |
Написание надежного управляемого кода в .NET Framework
2.0
Автор: Стивен Тауб (Stephen Toub), Microsoft
Перевод: Надежда Шатохина(sna@uneta.org), Ukraine .Net
Alliance (http://www.uneta.org/)
Октябрь 2005
Применяется к:
.NET Framework
SQL Server 2005
Обзор:
Эта статья ориентирована на
предварительную версию .NET Framework 2.0. Вся представленная здесь информация
может претерпеть изменения.
Введение
Подлость
Ограниченные области выполнения
Класс RuntimeHelpers
Контракты надежности
Явная подготовка
Обработка StackOverflowException
Хосты CLR и политики эскалации
Критические финализаторы и надежные дескрипторы
Критические области
FailFast и MemoryGates
Заключение
Об авторе
Необработанные исключения
Управляемые отладчики
Введение
Вы пишете надежный управляемый код? Очевидно, что когда задается такой
вопрос, хочется ответить «да». Вы используете блоки try/finally для
предопределенного высвобождения ресурсов и активно применяете самоочищаемые
объекты. Поэтому, конечно, ваш код надежен, верно? Работа выполнена на
отлично?
Как ни печально, но это еще не все. В контексте написания управляемого кода
надежность предполагает возможность выполнения последовательности
предопределенных действий даже в условиях исключительной ситуации. Это позволяет
гарантировать отсутствие утечек ресурсов и возможность управления стабильностью
состояния и не полагаться на выгрузку домена приложения (или еще хуже, на
перезапуски процесса) при выходе из любого состояния нарушения информации. К
сожалению, в Microsoft® .NET Framework не все исключения являются
предопределенными и синхронными, что усложняет задачу по написанию кода,
абсолютно детерминированного в его способности выполнять предопределенную
последовательность операций. А в .NET Framework 1.x некоторые ситуации делают
это практически невозможным. В данной статье я покажу, почему это происходит, и
затем рассмотрю новые возможности .NET Framework 2.0, помогающие смягчать эти
ситуации и писать более надежный код.
Основной пример, почему это важно: начиная с версии SQL Server™ 2005, SQL
Server может размещать общеязыковую среду выполнения (common language runtime –
CLR), что позволяет использование в управляемом коде хранимых процедур, функций
и триггеров. Поскольку доступ к хранимым процедурам должен быть быстрым, CLR
встраивается в процесс SQL Server. Для обеспечения высокой работоспособности
ASP.NET применяет повторное использование процессов: при выявлении некорректного
функционирования текущих рабочих процессов запускаются новые рабочие процессы.
Но SQL Server с его внутрипроцессным размещением не располагает такой роскошью;
он не может просто перезапустить рабочий процесс, поскольку при перезапуске
этого основного процесса базы данных возникнет простой. Поэтому в качестве
защиты от непрогнозируемых сбоев SQL Server выбирает изоляцию домена приложения,
чтобы можно было просто выгрузить домен приложения с ухудшающимися
характеристиками и заменить новой. Поэтому крайне важно, чтобы код,
выполняющийся на SQL Server, был максимально надежным, и чтобы в случае
нарушения общего состояния это нарушение было изолированным, и сервер мог
восстановиться. (Повреждение всего процесса может заставить SQL Server отключить
CLR.) Надежность важна для клиентских приложений, которые потребляют системные
ресурсы, и она исключительно важна для любого приложения, к которому
предъявляется требование обеспечения большого периода работоспособности, будь то
SQL Server, служба Windows® или любой другой хост или приложение, которому может
понадобится выполняться в течение длительных промежутков времени. Обеспечение
надежности своего кода является огромным шагом на пути к возможности выполнения
в этих средах.
Подлость
Я считаю, что в хорошей драме должен присутствовать недооцененный противник,
соперник, которому в иной ситуации вы, вероятно, сочувствовали бы. А злодеи
здесь все те же, полезные во многих ситуациях, и до сих пор являющиеся
источником постоянного раздражения в надежном коде. Они принимают образ
исключений OutOfMemoryException (нехватка памяти), StackOverflowException
(переполнение стека) и ThreadAbortException (аварийное прерывание потока).
Исключение OutOfMemoryException формируется при попытке получить для процесса
больше памяти в условиях, когда для удовлетворения потребности нет достаточного
количества непрерывной памяти. Обычно считается, что эти исключения возникают в
ответ на явные команды создания новых объектов в коде, т.е. на уровне
промежуточного языка Microsoft (Microsoft intermediate language – MSIL) это
команды newobj и newarr. Но к распределению памяти приводят и другие операции.
Упаковка (с помощью MSIL-команды box), например, требует выделения памяти в куче
для хранения типа значения. Вызов метода, который впервые использует некоторый
тип, приведет к отсроченной загрузке в память соответствующей сборки, таким
образом, потребуется распределение ресурсов. Выполнение ранее невыполняемого
метода приводит к его компиляции по запросу (just-in-time – JIT), при этом
необходима память для хранения генерируемого кода и ассоциированных с ним
структур данных времени выполнения. И так далее.
По правде говоря, распределение памяти в управляемом коде может происходить в
самые неожиданные моменты, что очень усложняет задачу корректной обработки этих
исключений, даже при активном использовании блоков try/catch/finally и
финализаторов. Что если для этих отменяющих изменения блоков кода и
финализаторов необходимо распределять память? Что если они еще не были
JIT-откомпилированы? Что если вызываемый вами метод выделяет память, как делают
многие API в самой Framework? По правде говоря, CLR в .NET Framework 1.x не
гарантирует, что отменяющий изменения код будет когда-либо выполнен. Отсутствие
гарантий выполнения ветвей отменяющего изменения кода чрезвычайно усложняет
создание приложений, надежно обрабатывающих условия нехватки памяти.
Исключение StackOverflowException тоже довольно проблематично. Оно имеет
место при переполнении стека выполнения текущего потока из-за слишком большого
количества незавершенных вызовов методов, что зачастую является результатом
высокой рекурсивности функций или большого стекового фрейма, занимающего
существенный объем стекового пространства, например, как тот, который использует
ключевое слово C# stackalloc (соответствующее команде MSIL localloc). Вызовы
некоторых методов, например, инициация методов другого домена приложения (при
этом используется технология .NET Remoting), могут также привести к
существенному потреблению стека, даже если самому целевому методу не требуется
большого количества памяти. Как и с OutOfMemoryException, CLR в .NET Framework
1.x не гарантирует выполнения отменяющего изменения кода; кстати, нет даже
никакой гарантии, что исключение StackOverflowException будет перехвачено. В
версии 1.x исключение формируется при возникновении переполнения в управляемом
коде, но если переполнение имеет место в среде выполнения, процесс будет
остановлен.
Когда Windows выявляет переполнение стека потока, процесс может попытаться
обработать ошибку. Однако если код обработки исключения процесса написан
неаккуратно, он может обусловить еще одно переполнение стека. Если один и тот же
поток переполняет стек дважды и не восстанавливает защитную страницу стека,
операционная система уничтожает процесс. Большинство приложений и библиотек даже
не пытаются справиться с этой проблемой, потому что очень сложно написать код,
который может пережить переполнение стека от каждого вызова метода (также при
обработке переполнений стека требуется раскрутка части стека, это означает, что
все ближайшие к точке переполнения блоки finally могут быть пропущены). Кстати,
в версии 1.x сама CLR при обработке переполнения стека от управляемого кода
может обеспечить переполнение стека, тогда операционная система уничтожает
процесс. В .NET Framework 2.0 CLR может с большой вероятностью выявлять
переполнения стека и затем, на основании политики хоста, принимать решение о
том, прервать ли процесс или формировать StackOverflowException и позволить
выполнение соответствующих управляемых блоков catch и finally.
Наверное, самым неприятным из всех является ThreadAbortException. Когда поток
вызывает Thread.Abort самостоятельно (например, Thread.CurrentThread.Abort),
результат не представляет особого интереса: формируется синхронное
ThreadAbortException. Проблема надежности возникает, когда поток использует
Abort, чтобы прервать другой поток, или когда вызывается AppDomain.Unload, что
имеет эффект вызова Abort для всех выполняющихся в настоящее время потоков
целевого домена приложения или потоков, имеющих существующий стековый фрейм
этого домена. Это заставляет среду выполнения вводить ThreadAbortException в
целевой поток, и это может произойти в целевом потоке между любыми двумя
машинными командами. Рассмотрим следующий код:
IntPtr memPtr = Marshal.AllocHGlobal(0x100);
try
{
... // используем распределенную управляемую память здесь
}
finally { Marshal.FreeHGlobal(memPtr); }
Что если ThreadAbortException формируется после распределения памяти, но
перед входом в блок try? Блок finally не будет выполнен (поскольку в
соответствующем блоке try исключения не было), и теперь имеется утечка памяти,
поскольку сборщик мусора (garbage collector – GC) ничего не знает об этом
неуправляемом участке памяти. Можно было бы попытаться переписать код так, чтобы
распределение происходило в блоке try, но это не поможет, если исключение имеет
место после возвращения AllocHGlobal и перед выполнением машинной команды на
сохранение этого значения в memPtr. Указатель на выделенный участок памяти будет
утерян, и произойдет утечка памяти.
Альтернативный вариант, что если исключение возникает в блоке finally (это
может произойти в .NET Framework 1.x и в определенных сценариях .NET Framework
2.0)? Вкратце, если пользовательский код не имеет возможности обозначения
участков кода, которые не могут быть прерваны исключениями ThreadAbortException,
практически невозможно написать надежный код, устойчивый к асинхронным
исключениям.
Ограниченные области выполнения
.NET Framework 2.0 представляет Ограниченные области выполнения (Constrained
Execution Regions – CER), которые налагают ограничения как на среду выполнения,
так и на разработчика. В части кода, отмеченной как CER, среда выполнения не
может формировать определенные асинхронные исключения, которые могли бы помешать
полному выполнению этой части кода. Ограничиваются также действия разработчика,
которые он может осуществить в этой части. Этим самым создается инфраструктура и
принудительный механизм написания надежного управляемого кода, что делает их
ключевым игроком в схеме надежности .NET Framework 2.0.
Существует несколько соглашений для CER. Во-первых, среда выполнения будет
откладывать прерывание потоков для кода, который выполняется в CER. Иначе
говоря, если поток вызывает Thread.Abort для прекращения другого потока, который
в настоящий моменты выполняется в CER, среда выполнения не прервет целевой поток
до тех пор, пока будет выполняться CER. Во-вторых, среда выполнения будет
компилировать CER как можно раньше, чтобы избежать возникновения условий
нехватки памяти. Это означает, что среда выполнения будет делать все, что в
обычных условиях осуществлялось бы во время JIT-компиляции участка кода,
заранее. Выполняя эту работу предварительно, среда выполнения может повысить
вероятность предупреждения исключений, которые могли бы возникнуть в этой части
кода и помешать соответствующей очистке ресурсов.
Для эффективного использования CER разработчики должны избегать определенных
действий, которые могут привести к формированию асинхронных исключений. Код не
может осуществлять определенные действия, включая такие вещи, как явные
распределения памяти, упаковка, вызовы виртуальных методов (если только цель
вызова виртуального метода уже не была подготовлена), вызовы методов с
использованием технологии Reflection, применение Monitor.Enter (или ключевого
слова lock в C# и SyncLock в Visual Basic®), команд isinst и castclass
COM-объектов, доступ к полям через прозрачные прокси, сериализцию и доступ к
многомерным массивам.
Короче говоря, CER – это способ переместить любую точку сбоя, сформированную
средой выполнения, из вашего кода на момент или перед выполнением кода (в случае
JIT-компиляции), или после завершения выполнения (для аварийных прерываний
потоков). Однако CER на самом деле ограничивают возможности кода. Такие
ограничения, как запрещение большинства распределений или вызовов виртуальных
методов неподготовленных целевых объектов, являются значительными и приводят к
большим затратам при разработке. Это значит, что CER не подходят для больших
фрагментов кода общего назначения и должны рассматриваться только как средство,
гарантирующее выполнение небольших участков кода.
Класс RuntimeHelpers
По умолчанию среда выполнения не предполагает, что код находится в
ограниченной области выполнения. Разработчик должен явно обозначать, какие
участки кода должны быть защищены и подготовлены, с помощью методов класса
System.Runtime.CompilerServices.RuntimeHelpers. Самый важный метод этого класса
– статический метод PrepareConstrainedRegions. Этот метод может проверять
наличие достаточного пространства в стеке и выполнять роль маркера для CLR,
сообщая ей о начале CER. На уровне MSIL он должен следовать непосредственно
перед блоком try и превращает его в «надежный try», гарантируя, что все
необходимые отменяющему изменения коду ресурсы выделены заранее (таким образом,
защищая эту область кода от сгенерированных CLR исключений, вызванных нехваткой
памяти). Он также гарантирует, что любые аварийные прерывания потоков будут
отложены до завершения выполнения отменяющего изменения кода.
Обратите внимание, что подготовлен только код, находящийся в блоках catch,
finally, fault и filter, ассоциированных с блоком try, не в самом try. Код блока
try по-прежнему может формировать исключение OutOfMemoryException при
JIT-компиляции или быть прерванным ThreadAbortException. Однако поскольку
отменяющий изменения код уже подготовлен, соответствующие блоки catch, finally,
fault и filter смогут выполняться и обрабатывать эти исключения. (Если бы этот
код не был подготовлен заранее, ситуация нехватки памяти могла бы помешать
выполнению отменяющего изменения кода.) Фрагмент кода на Visual Basic
демонстрирует, какой код будет и не будет подготовлен (хотя здесь не показаны
блоки fault, поскольку они в настоящий момент недоступны для всех языков
Microsoft, кроме MSIL).
Imports System
Imports System.Runtime.CompilerServices
Class RegionsDemo
Shared Sub Main()
... ' не будет подготовлен
RuntimeHelpers.PrepareConstrainedRegions()
Try
... ' не будет подготовлен
Catch exc As SomeException When SomeFilter(exc)
... ' будет подготовлен
Finally
... ' будет подготовлен
End Try
... ' не будет подготовлен
End Sub
Shared Function SomeFilter(ByVal exc as Exception) As Boolean
... ' будет подготовлен
End Function
End Class
Поскольку код, находящийся в блоке try, отмеченном как
PrepareConstrainedRegions, не будет подготовлен, зачастую можно будет увидеть
(и, вероятно, найти полезным) следующий шаблон создания области кода, которую
невозможно прервать:
RuntimeHelpers.PrepareConstrainedRegions();
try {} finally
{
... // здесь находится ваш непрерываемый код
}
Здесь вместо того, чтобы выполнять роль отменяющего изменения кода,
используемого для восстановления состояния, измененного в блоке try, блок
finally содержит код, который осуществляет дальнейшие изменения.
Кроме подготовки кода в блоках отменяющего изменения кода, результат
применения PrepareConstrainedRegions является транзитивным, т.е. CLR будет
проходить по всей схеме вызываемых функций от отменяющего изменения кода и
подготавливать все встречающиеся в ней методы. Однако существует несколько
ограничений относительно того, какие методы будут подготавливаться. Во-первых,
CLR может подготовить лишь те методы, которые может найти. Если используется
непрямой доступ, например, вызов через интерфейс, делегат, виртуальный метод или
отражение (reflection), CLR не сможет отследить цель по схеме вызываемых функций
и, таким образом, цель не будет подготовлена. В результате, по-прежнему во время
выполнения могут иметь место исключения, вызванные нехваткой памяти, и аварийные
прерывания потоков не будут откладываться соответствующим образом. Во-вторых,
каждый метод схемы вызываемых функций должен быть охвачен соответствующим
контрактом надежности.
Контракты надежности
Чтобы среда выполнения подготовила CER, ей должно быть известно, что код этой
CER и схема вызываемых функций поддерживают ограничения, необходимые для
выполнения в CER. Для этого .NET Framework предоставляет
ReliabilityContractAttribute (атрибут контракта надежности) в пространстве имен
System.Runtime.ConstrainedExecution.
[AttributeUsage(AttributeTargets.Interface | AttributeTargets.Method |
AttributeTargets.Constructor | AttributeTargets.Struct |
AttributeTargets.Class | AttributeTargets.Assembly, Inherited=false)]
public sealed class ReliabilityContractAttribute : Attribute
{
public ReliabilityContractAttribute(
Consistency consistencyGuarantee, CER cer);
public Cer Cer { get; set; }
public Consistency ConsistencyGuarantee { get; set; }
}
[Serializable]
public enum Cer { None = 0, MayFail = 1, Success = 2 }
[Serializable]
public enum Consistency
{
MayCorruptProcess = 0, MayCorruptAppDomain = 1,
MayCorruptInstance = 2, WillNotCorruptState = 3
}
Контракт надежности выражает две разные, но взаимосвязанные, концепции: к
нарушению состояния какого типа могут привести асинхронные исключения,
формируемые во время выполнения метода, и какие гарантии завершения может
обеспечить метод, если он выполняется в CER. Кроме предоставления на уровне
методов, контракты также могут быть определены на уровнях класса и сборки.
Контракты уровня метода обладают приоритетом по сравнению с контрактами уровня
класса или сборки, и контракты классов приоритетней контрактов уровня
сборки.
Первая часть контракта выражается через свойство ConsistencyGuarantee
(гарантия согласованности) атрибута, которое принимает значение из перечисления
Consistency (согласованность). Это свойство описывает уровень нарушения
состояния, которое может произойти в результате формирования асинхронного
исключения во время выполнения метода. (Рассматривайте это как шаблон,
используемый для обеспечения вызывающему некоторого представления о том, как
вернуться в нормальное состояние.) Наихудшим видом нарушений является нарушение
процесса (MayCorruptProcess – возможно повреждение процесса), который
используется для индикации того, что рассматриваемый метод на момент
формирования исключения, возможно испортил состояние, затрагивающие весь
процесс. Таким образом, теперь состояние может быть несогласованным. Аналогично,
MayCorruptAppDomain (возможно повреждение домена приложения) сигнализирует о
том, что метод, возможно, повредил состояние домена приложения (например,
статической переменной), и таким образом, это состояние может быть
несогласованным (хотя общее состояние процесса по-прежнему должно оставаться
согласованным). MayCorruptInstance (возможно повреждение экземпляра)
используется для предупреждения о том, что метод мог оставить экземпляр в
несогласованном состоянии (но не более того), и WillNotCorruptState (не повредит
состояние) означает, что метод не мог привести к несогласованности состояния
(обычно используется для методов, которые просто считывают информацию
состояния).
Свойство Cer и перечисление используются для обозначения гарантий завершения,
предоставляемых методом в случае выполнения в CER (если он не находится в CER,
все эти гарантии ничего не стоят). Значение Success (Успешно) показывает, что
этот метод при выполнении в CER, предполагая действительность входных данных,
всегда будет завершаться успешно; метод, обозначенный как Success, может
формировать исключения в случае предоставления ему недействительных
параметров.
Значение MayFail (возможен сбой) свойства Cer используется для предупреждения
о том, что при возникновении асинхронных исключений код может не завершиться
так, как ожидается. Поскольку в ограниченных областях выполнения прерывания
потоков откладываются, это на самом деле означает, что код делает что-то, что
может привести к распределению памяти или переполнению стека. Что еще более
важно, это значит, что при вызове данного метода необходимо учитывать возможные
сбои.
Для корневых методов схемы вызываемых функций CER допустимыми являются только
три комбинации значений Cer и Consistency:
[ReliabilityContract(Consistency.MayCorruptInstance, Cer.MayFail)]
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.MayFail)]
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
Первая показывает, что в исключительных условиях метод может дать сбой, но в
самом худшем случае он повредить лишь конкретный экземпляр; домен приложения и
состояние всего процесса останутся нетронутыми. Вторая показывает, что метод
может дать сбой, но даже в этом случае все состояние по-прежнему будет
действительным. Это соответствует тому, что сообщество C++-разработчиков
называет «строгая гарантия исключения», имея ввиду, что действие завершается или
дает сбой без негативных побочных эффектов или формирования исключения. Третья
подразумевает, что метод всегда будет завершаться успешно и ни в коем случае ни
одно из состояний не будет повреждено. Эта последняя пара обеспечивает самую
прочную из возможных гарантию, но поэтому так могут быть обозначены лишь
некоторые методы. Кстати, у большинства из методов, с которыми вам придется
работать, значение Cer будет равно None или вообще будет отсутствовать контракт
надежности. Это означает, что метод вообще не предоставляет никаких гарантий в
условиях исключения. Cer.None и Consistency.MayCorruptProcess обозначают
отсутствие контракта надежности для метода.
При задании контрактов надежности для собственных методов помните, что
понижение своих гарантий Cer или Consistency считается пагубным изменением.
Вызывающая сторона, возможно, ориентируются на ваш уровень надежности, и изменяя
его, можно нарушить эти зависимости. Разумным будет не определять контракты
надежности в первом приближении до тех пор, пока не известно наверняка, какие из
методов будут использоваться из ограниченных областей выполнения.
Также существует несколько интересных вопросов трактовки контрактов
надежности. Например, одна из проблем, с которыми сталкиваются разработчики CLR
– большинство хорошо реализованных методов проверяют свои параметры и формируют
исключения, если входные данные недействительны. Таким образом, подход,
состоящий в простом запрещении всех распределений памяти из CER, был бы
практически бесполезным (некоторые методы также могут проводить распределение и
затем восстанавливать свое состояние после любого исключения, вызванного
нехваткой памяти). Контракты надежности – это попытка убрать этот тип
детализации из среды выполнения, обеспечивая возможность автору кода четко
определить, нужно ли вызывающей стороне заботиться о сбоях, и если да, до какого
момента необходимо вернуть состояние. Как следствие, контракты надежности
считаются неопределенными (null) и пустыми (void), если передаваемые в метод
аргументы недопустимы или метод используется неправильно. Кроме того, возможны
концепции, которые трудно выразить посредством контрактов. Представьте себе
метод, который принимает в качестве параметра тип Object и вызывает его метод
Equals. Этот метод может быть надежным, но только в том случае, если в него
передается объект, имеющий надежный переопределенный метод Equals. В настоящее
время не существует встроенной возможности выразить эту концепцию.
Явная подготовка
Как упоминалось ранее, если задано PrepareConstrainedRegions (подготовить
ограниченные области), среда выполнения пройдет по всем схемам вызываемых
функций, выходящим из корня CER. К сожалению, среда выполнения не всеведуща и не
может определить, какой метод вызывается из виртуальных вызовов. Таким образом,
если из ограниченной области используется интерфейс, виртуальный метод, делегат
или обобщенный (generic) метод, среда выполнения, вероятно, не сможет заранее
подготовить целевые методы, поскольку они не будут определены вплоть до времени
выполнения (или в случае шаблонов, они могут быть определены, но по-прежнему
будет необходимо выделение некоторого количества памяти при первом вызове этого
метода с определенными параметрами). Чтобы помочь CLR, разработчик может
использовать два дополнительных метода класса RuntimeHelpers: PrepareMethod
(подготовить метод) и PrepareDelegate (подготовить делегат). Метод PrepareMethod
принимает RuntimeMethodHandle для MethodBase целевого метода. Во время
выполнения код может получить идентификатор метода, который должен быть вызван,
и затем использовать PrepareMethod для его подготовки перед входом в CER.
Например, рассмотрим первый фрагмент нижеприведенного кода. BaseObject
предоставляет виртуальный метод VirtualMethod, используемый в CER. Поскольку он
виртуальный, CLR не может посредством статического анализа определить
фактическую цель инициации. Если, на самом деле, в SomeMethod передается объект
DerivedObject, переопределенный метод VirtualMethod объекта DerivedObject к
моменту вызова может не быть подготовлен, таким образом, подвергая риску CER.
Чтобы выйти из этой ситуации, можно применить PrepareMethod, как только цель
станет известной. Конечно, применение reflection для получения дескрипторов
методов может быть дорогостоящей операцией. Если все методы, которые могут быть
вызваны, известны, можно рассмотреть возможность проведения всей
подготовительной работы заранее, например, в статическом конструкторе.
Неверный вызов виртуального метода в CER
public void SomeMethod(BaseObject o)
{
RuntimeHelpers.PrepareConstrainedRegions();
try { ... } finally { o.VirtualMethod(); }
}
Исправленный вызов виртуального метода в CER
public void SomeMethod(BaseObject o)
{
RuntimeHelpers.PrepareMethod(
o.GetType().GetMethod("VirtualCall").MethodHandle));
RuntimeHelpers.PrepareConstrainedRegions();
try { ... } finally { o.VirtualMethod(); }
}
Предварительная подготовка в случае, если все цели известны заранее
static SomeType()
{
foreach (Type t in
new Type[]{typeof(DerivedType1), typeof(DerivedType2), ...})
{
RuntimeHelpers.PrepareMethod(
t.GetMethod("VirtualMethod").MethodHandle);
}
}
public void SomeMethod(BaseObject o)
{
RuntimeHelpers.PrepareConstrainedRegions();
try { ... } finally { o.VirtualMethod(); }
}
PrepareDelegate подобен PrepareMethod. Он принимает делегат и подготавливает
указанный метод. PrepareDelegate готовит только конкретный указанный делегат и
не касается делегатов, связанных с этим делегатом. То есть даже если групповой
делегат состоит из нескольких делегатов, подготовлен будет только тот, на
который имеется явная ссылка. Если делегат будет инициироваться из CER, должен
быть или извлечен список вызовов делегата и подготовлен каждый отдельный
делегат, или каждый конкретный делегат должен быть подготовлен еще до
объединения с остальными делегатами. Здесь возможны различные варианты для
событий. Если есть событие, вызов которого планируется из CER, для него можно
рассмотреть возможность предоставления специального аксессора add, который будет
подготавливать делегаты, перед объединением нового делегата с любым ранее
зарегистрированным:
public event EventHandler MyEvent {
add {
if (value == null) return;
RuntimeHelpers.PrepareDelegate(value);
lock(this) _myEvent += value;
}
remove { lock(this) _myEvent -= value; }
}
Вот как реализовываются несколько событий AppDomain, такие как ProcessExit и
DomainUnload, которые формируются в CER.
Если PrepareMethod и PrepareDelegate не используются там, где должны били бы
присутствовать, отследить проблемы может быть сложно. CLR предоставляет
несколько управляемых отладчиков (managed debug assistants – MDA) для
диагностики таких связанных с CER проблем. Более подробно смотрите в разделе
Управляемые отладчики.
Обработка StackOverflowException
CLR никак не гарантирует выполнение соответствующего отменяющего изменения
кода в случае применения StackOverflowException в блоке try. Чтобы обеспечить
сценарии, в которых в случае возникновения исключений StackOverflowException
отменяющий изменения код должен быть выполнен обязательно, класс RuntimeHelpers
предоставляет метод ExecuteCodeWithGuaranteedCleanup. Этот метод принимает три
параметра: делегат RuntimeHelpers.TryCode, содержащий код для выполнения в блоке
try, делегат RuntimeHelpers.CleanupCode, содержащий код для выполнения в блоке
finally, и пользовательские данные, которые будут поставляться в оба делегата.
Пример использования этого метода показан в следующем коде:
try
{
RuntimeHelpers.ExecuteCodeWithGuaranteedCleanup(
TryMethod, CleanupMethod, this);
}
catch(Exception exc) { ... } // Обработка неожиданного сбоя
...
[MethodImpl(MethodImplOptions.NoInlining)]
void TryMethod(object userdata) { ... }
[MethodImpl(MethodImplOptions.NoInlining)]
[ReliabilityContract(Cer.Success, Consistency.MayCorruptInstance)]
[PrePrepareMethod] // Для обеспечения лучшей производительности, если был создан образ с помощью ngen.
void CleanupMethod(object userdata, bool fExceptionThrown) { ... }
ExecuteCodeWithGuaranteedCleanup создает обработчик структурной обработки
исключений (structured exception handling – SEH) в CLR. При наличии такой
защиты, метод выполняет управляемый код TryCode. Если при выполнении этого кода
возникает переполнение стека, среда выполнения выявляет эту ошибку и
обеспечивает существование достаточного пространства в стеке для нормального
выполнения CleanupCode. Конечно, по-прежнему необходимо гарантировать, чтобы сам
отменяющий изменения код не вызывал переполнения стека (он не должен
осуществлять высокорекурсивных вызовов или зависеть от кода, требующего большого
или неизвестного количества пространства стека). К слову, заметьте, что C# в
настоящее время не позволяет задавать специальный атрибут для анонимного метода,
поэтому постарайтесь не использовать анонимных методов в отменяющем изменения
коде.
Хосты CLR и политики эскалации
В каких случаях в условиях нехватки памяти исключения OutOfMemoryException не
возникает? Когда хост CLR запрещает это. Неуправляемое приложение, размещающее
CLR, может контролировать то, как среда выполнения реагирует на определенные
ситуации, включая сбои при распределении ресурсов, сбои при распределении
ресурсов в критических областях кода, зависшие блокировки и фатальные ошибки в
самой среде выполнения. Посредством неуправляемого интерфейса ICLRPolicyManager
хост может контролировать действия, предпринимаемые CLR при возникновении
определенных ошибок. Эти действия включают формирование исключений, прерывание
потоков, выгрузку доменов приложений, выход из процесса, отключение среды
выполнения и невыполнение вообще никаких действий (игнорирование сбоя).
Формирование исключений и игнорирование сбоев применяются стандартным хостом
CLR. Например, если память выделить невозможно, среда выполнения формирует
исключение OutOfMemoryException, и если среда выполнения получает предупреждение
о зависшей блокировке, она игнорирует проблему. С помощью ICLRPolicyManager и
его метода SetActionOnFailure (задать действие на случай сбоя) хост может менять
эти применяемые по умолчанию настройки. Это значит, что в случае невозможности
распределения памяти хост, выбрав ThreadAbortException, а не
OutOfMemoryException, может заставить среду выполнения аварийно завершить поток.
При обнаружении зависшей блокировки хост может заставить среду выполнения
выгрузить домен приложения, а не игнорировать ошибку. При написании кода
необходимо помнить об этих возможностях.
Данных типов политик не достаточно для всех хостов. Иногда хосту необходима
возможность расширения перечня доступных реакций, если предыдущего действия
оказалось не достаточно. Например, рассмотрим, что происходит, если в блоке try
формируется ThreadAbortException, а блок finally, ассоциированный с этим try,
приводит к бесконечному циклу. При использовании применяемой по умолчанию
политики среды выполнения этот поток никогда не будет прерван, и неуправляемому
хосту, которому необходимы гарантии надежности, нужен какой-то способ выхода из
этой ситуации. Решение приходит в форме метода SetTimeoutAndAction (задать время
ожидания и действие) класса ICLRPolicyManager (и в меньшей степени его метод
SetDefaultAction (задать применяемое по умолчанию действие)). Этот метод
принимает три параметра: действие, время ожидания и ответное действие. Если в
настоящее время среда выполнения осуществляет действие, имеющее время ожидания,
и это время истекает, среда выполнения обновит это действие ответным. Например,
хост мог бы задать, что прерывание всех потоков должно занимать не более пяти
секунд и по истечении этого времени домен приложения должна быть выгружена. У
самой среды выполнения есть только одно применяемое по умолчанию время ожидания,
и оно используется для выхода из процесса. Если примерно за 40 секунд выйти из
процесса не удается (завершение всех потоков, выгрузка всех доменов приложений и
т.д.), среда выполнения завершает процесс.
Ранее я упоминал, что в ответ на определенные сбои хост может предпринимать
различные действия, включая прерывание потоков и выгрузку доменов приложений. Я
не сказал о том, что некоторые из этих действий, включая аварийное прерывание
потоков, выгрузку доменов приложений и выходы из процессов, имеют несколько
уровней серьезности. До сих мы просто говорили об аварийных прерываниях потоков
как результате формирования средой выполнения ThreadAbortException для потока.
Обычно это приводит к завершению потока. Однако поток может обрабатывать
аварийное прерывание потока, предотвращая завершение потока. Учитывая это, среда
выполнения предоставляет более мощное средство с очень точным названием:
внезапное прерывание потока. При внезапном прерывании поток прекращает
выполнение. Когда это происходит, CLR не гарантирует выполнение отменяющего
изменения кода для потока (если только код не выполняется в CER). В самом деле,
внезапно.
Аналогично, тогда как обычная выгрузка домена приложения постепенно завершит
все потоки домена, при внезапной выгрузке домена приложения все потоки будут
прерваны внезапно и не будет обеспечено выполнение обычных финализаторов,
ассоциированных с объектами этого домена. SQL Server 2005 – это один из хостов
CLR, использующих внезапные прерывания потоков и внезапные выгрузки доменов
приложений как часть своей политики эскалации. При возникновении асинхронного
исключения сбой распределения ресурсов будет заменен более высоким по статусу
аварийным прерыванием потока. И аварийное прерывание потока, если оно не будет
завершено в течение промежутка времени, установленного SQL Server, будет
заменено внезапным прерыванием потока. Аналогичным образом, если операция
выгрузки домена приложения не будет завершена в течение установленного SQL
Server промежутка времени, она будет превращена во внезапную выгрузку домена
приложения. (Обратите внимание, что приведенные политики являются не вполне тем,
что использует SQL Server, поскольку SQL Server также учитывает то, выполняется
ли код в критических областях, но более подробно об этом чуть ниже).
Важно усвоить, что CLR обрабатывает постепенные прерывания потоков иначе, чем
внезапные. В .NET Framework 1.x нет такого понятия, как внезапное прерывание
потока, и прерывания потоков могут быть инициированы в любом месте управляемого
кода, без всякой защиты, предоставляемой CLR. В .NET Framework 2.0 CLR по
умолчанию откладывает постепенные прерывания потоков с помощью CER, блоков
finally, блоков catch, статических конструкторов и неуправляемого кода. Однако
внезапные прерывания могут быть отложены только через CER и неуправляемый код
(CLR практически не контролирует последнее).
Внезапные прерывания потоков и внезапные выгрузки доменов приложений
используются хостами CLR, чтобы обеспечить возможность управления вышедшим
из-под контроля кодом. Конечно, невозможность запуска финализаторов или не CER
блоков finally ставит перед хостом CLR новые проблемы надежности, поскольку
велика вероятность того, что эти действия приведут к утечке ресурсов, которые
должны были бы быть очищены отменяющим изменения кодом. Слава Богу есть
критические финализаторы.
Критические финализаторы и надежные дескрипторы
Постепенное прерывание потоков сделает возможным выполнение любых
соответствующих блоков finally, что не гарантируется при внезапном прерывании
потоков (только в CER). Постепенная выгрузка домена приложения использует
постепенные прерывания потоков и обеспечит возможность выполнения всех
соответствующих блоков finally и финализаторов объектов этого домена, чего
нельзя сказать о внезапных выгрузках домена приложения (только в CER). При
внезапных выгрузках домена приложения среда выполнения не гарантирует выполнения
отменяющего изменения кода или обычных финализаторов. Как же может система быть
надежной при таких условиях?
.NET Framework 2.0 представляет новый тип финализаторов, называемых
критическими финализаторами. Критический финализатор – это особый вид
финализаторов, выполняемых даже при внезапной выгрузке домена приложения, и они
запускаются в CER. Применение критических финализаторов должно быть ограничено
только для наиболее важных финализаторов, необходимых для обеспечения
безопасности или надежности. Лишь некоторые классы .NET Framework используют
критические финализаторы.
Чтобы реализовать критический финализатор, просто унаследуйте данный класс от
класса CriticalFinalizerObject пространства имен
System.Runtime.ConstrainedExecution:
[SecurityPermission(
SecurityAction.InheritanceDemand, UnmanagedCode=true)]
public abstract class CriticalFinalizerObject
{
protected CriticalFinalizerObject();
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
protected override void Finalize();
}
Любой финализатор, реализуемый в унаследованном классе, будет вызываться как
часть CER, и должен иметь гарантии надежности, соответствующие указанным в
контракте надежности для CriticalFinalizerObject.Finalize. Иначе говоря, если
при вызове в рамках CER гарантируется, что финализатор будет успешно выполнен и
не повредит какого-либо состояния, необходимо просто наследоваться от
CriticalFinalizerObject. Среда выполнения подготавливает метод Finalize прямо
при создании экземпляра объекта, унаследованного от CriticalFinalizerObject,
поэтому когда приходит время впервые выполнить метод, нет необходимости
JIT-компилировать какой-либо код (или выполнят другие подготовительные
операции).
Один из классов .NET Framework, наследующихся от CriticalFinalizerObject –
SafeHandle, находящийся в пространстве имен System.Runtime.InteropServices.
SafeHandle является долгожданным дополнением к .NET Framework и имеет большое
значение для решения многих связанных с надежностью проблем, присутствующих в
предыдущих версиях. По сути, SafeHandle – это просто управляемая оболочка для
IntPtr, снабженная финализатором, который знает, как высвобождать основные
ресурсы, используемые этим IntPtr. Поскольку SafeHandle наследуется от
CriticalFinalizerObject, подготовка этого финализатора происходит при создании
экземпляра SafeHandle, и вызывается он из CER, чтобы гарантировать, что
асинхронные прерывания потоков не прервут выполнение финализатора.
Рассмотрим функцию FindFirstFile (найти первый файл) Win32, которая
используется для перебора файлов каталога:
HANDLE FindFirstFile(
LPCTSTR lpFileName, LPWIN32_FIND_DATA lpFindFileData);
В .NET Framework 1.x объявление метода P/Invoke для этой функции обычно
описывается следующим образом:
[DllImport("kernel32.dll", CharSet=CharSet.Auto, SetLastError=true)]
private static extern IntPtr FindFirstFile(
string pFileName, [In, Out] WIN32_FIND_DATA pFindFileData);
К сожалению, если после возвращения из FindFirstFile, но перед сохранением
результирующего дескриптора IntPtr, формируется асинхронное исключение,
происходит утечка ресурса операционной системы без особой надежды на его
высвобождение. На помощь приходит SafeHandle. В .NET Framework 2.0 можно
переписать данную сигнатуру следующим образом:
[DllImport("kernel32.dll", CharSet=CharSet.Auto, SetLastError=true)]
private static extern SafeFindHandle FindFirstFile(
string fileName, [In, Out] WIN32_FIND_DATA data);
Единственное отличие в том, что мы заменили возвращаемый тип IntPtr на
SafeFindHandle, где SafeFindHandle – специальный тип, производный от SafeHandle.
Когда среда выполнения инициирует вызов FindFirstFile, сначала создается
экземпляр SafeFindHandle. По завершении выполнения FindFirstFile, среда
выполнения сохраняет возвращенный IntPtr в уже созданный SafeFindHandle. Среда
выполнения гарантирует, что эта операция является атомарной, т.е. в случае
успешного выполнения метода P/Invoke IntPtr будет благополучно сохранен в
SafeHandle. Оказавшись в SafeHandle, даже в случае возникновения асинхронного
исключения, препятствующего сохранению возвращаемого значения SafeFindHandle
метода FindFirstFile, соответствующий IntPtr уже сохранен в управляемом объекте,
финализатор которого будет гарантировать его надлежащее высвобождение.
Внутри .NET Framework использует большое количество производных от SafeHandle
типов: по одному на каждый тип используемых неуправляемых ресурсов. Открыто
предоставляются только некоторые из них, включая SafeFileHandle (используемый
как оболочка для дескрипторов файлов) и SafeWaitHandle (используемый как
оболочка для дескрипторов синхронизации). Конечно при работе с любыми не
рассмотренными здесь неуправляемыми ресурсами можно создавать собственные
производные от SafeHandle типы. Ниже приведены некоторые примеры реализации
таких дескрипторов.
SafeHandle для памяти из кучи:
[SecurityPermission(SecurityAction.LinkDemand, UnmanagedCode=true)]
public sealed class SafeLocalAllocHandle :
SafeHandleZeroOrMinusOneIsInvalid
{
[DllImport("kernel32.dll")]
public static extern SafeLocalAllocHandle LocalAlloc(
int uFlags, IntPtr sizetdwBytes);
private SafeLocalAllocHandle() : base(true) { }
protected override bool ReleaseHandle()
{
return LocalFree(handle) == IntPtr.Zero;
}
[SuppressUnmanagedCodeSecurity]
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
[DllImport("kernel32.dll", SetLastError=true)]
private static extern IntPtr LocalFree(IntPtr handle);
}
SafeHandle для LoadLibrary
[SecurityPermission(SecurityAction.LinkDemand, UnmanagedCode=true)]
public sealed class SafeLibraryHandle : SafeHandleZeroOrMinusOneIsInvalid
{
[DllImport("kernel32.dll", SetLastError=true)]
public static extern SafeLibraryHandle LoadLibrary(
string lpFileName);
private SafeLibraryHandle() : base(true) { }
protected override bool ReleaseHandle()
{
return FreeLibrary(handle);
}
[SuppressUnmanagedCodeSecurity]
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
[DllImport("kernel32.dll", SetLastError=true)]
private static extern bool FreeLibrary(IntPtr hModule);
}
Для облегчения написания собственных типов .NET Framework предоставляет два
дополнительных открытых производных от SafeHandle типа:
SafeHandleZeroOrMinusOneIsInvalid и SafeHandleMinusOneIsInvalid. SafeHandle
должен иметь возможность сообщить, является ли хранящийся в нем IntPtr
допустимым для соответствующего типа ресурса. Поскольку преимущественное
большинство дескрипторов ресурсов в мире Win32 считаются недействительными, если
имеют значения -1 или 0 и -1, были предоставлены данные классы, содержащие эти
проверки, что избавляет разработчиков от необходимости создавать их
самостоятельно.
Кроме управления жизненным циклом ресурсов, надежные дескрипторы обеспечивают
и другие преимущества. Во-первых, они оказывают поддержку в управлении памятью,
сокращая граф объектов, готовых к финализации. В .NET Framework 1.x класс,
которому требуются неуправляемые ресурсы, обычно хранит соответствующий IntPtr в
классе вместе со всеми остальными используемыми управляемыми объектами. Этот
класс почти наверняка реализует финализатор для обеспечения надлежащего
высвобождения IntPtr. Поскольку подлежащие финализации объекты всегда
переживают, по крайней мере, одну сборку мусора, в результате весь граф (вся
схема вызовов) объекта, начиная от класса, о котором идет речь, переживает
сборку мусора, и все из-за этого единственного IntPtr. Поскольку SafeHandle
теперь замещает IntPtr, и т.к. у SafeHandle есть собственный финализатор, в
большинстве сценариев класс, хранящий SafeHandle больше не нуждается в
собственном финализаторе. Тем самым оптимизируется граф объектов и сокращается
время сборки мусора. Кроме того, удаление финализатора обычно означает, что
можно избавиться от обращений к GC.KeepAlive(this) в этих объектах.
Надежные дескрипторы также помогают закрыть возможные пробелы в системе
безопасности, присутствующие из-за проблем повторного использования
дескрипторов. Windows поддерживает внутренние таблицы, проецирующие дескрипторы
в ассоциированные с ними объекты ядра. После высвобождения дескриптора Windows
вольна повторно использовать его для указания на другой ресурс. При определенных
условиях хакер может с помощью нескольких потоков воспользоваться этим свойством
дескрипторов, закрывая дескриптор в одном потоке и используя его в другом,
надеясь что Windows переназначит этот дескриптор другому ресурсу, таким образом,
предоставляя хакеру возможность доступа к ресурсу, недоступному в противном
случае. Чтобы устранить эту возможность, SafeHandle реализует подсчет ссылок.
При передаче SafeHandle в метод P/Invoke среда выполнения дает приращение
счетчика использования SafeHandle. По завершении P/Invoke, показание счетчика
использований уменьшается. При вызове методов Dispose или Close SafeHandle
происходит проверка его счетчика использований. Если значение счетчика равно 0,
дается разрешение на продолжение операции. Если счетчик больше 0, операция
откладывается до того момента, пока значение счетчика не будет равняться 0.
Таким образом обеспечивается невозможность реализации через SafeHandle атак с
применением повторного использования дескрипторов. Такой подсчет ссылок требует
минимальных затрат. Если по какой-то причине эти затраты для определенной
ситуации слишком велики, можно использовать класс CriticalHandle, также из
пространства имен System.Runtime.InteropServices. Класс CriticalHandle
аналогичен SafeHandle за исключением того, что не реализует подсчета ссылок.
Использовать SafeHandle просто. Рассмотрим реализацию SafeLibraryHandle,
приведенную на предыдущем листинге. Этот класс используется для сохранения
дескриптора, предоставленного LoadLibrary. Поскольку LoadLibrary использует
подсчет ссылок, чтобы гарантировать высвобождение библиотек только лишь после
высвобождения всех ссылок, важно обеспечить каждому вызову LoadLibrary
соответствующий вызов FreeLibrary. И т.к. LoadLibrary возвращает дескриптор, он
идеально подходит для SafeHandle. Весьма распространенным требованием,
предъявляемым к .NET Framework 1.x, была возможность использования
функциональности P/Invoke для динамической инициации неуправляемой функции во
время выполнения. Ниже показан пример реализации этого в .NET Framework 2.0.
[return: MarshalAs(UnmanagedType.Bool)]
private delegate bool ReturnBooleanHandler();
[DllImport("kernel32.dll")]
private static extern IntPtr GetProcAddress(
SafeLibraryHandle hModule, string procname);
...
using (SafeLibraryHandle lib =
SafeLibraryHandle.LoadLibrary("user32.dll"))
{
IntPtr procAddr = GetProcAddress(lib, "LockWorkStation");
Delegate d = Marshal.GetDelegateForFunctionPointer(
procAddr, typeof(ReturnBooleanHandler));
d.DynamicInvoke();
}
Критические области
Критические области используются для обозначения того, что код, выполняющийся
в этой области, удерживает блокировку и, возможно, редактирует совместно
используемое состояние. По существу, это другая форма счетчика блокировок.
Воздействие аварийного прерывания потока или необрабатываемого исключения в
рамках критической области может быть не ограничено только текущей задачей
(изменения в политике необрабатываемых исключений в .NET Framework 2.0 смотрите
во врезке Необработанные исключения). Рассмотрим следующий фрагмент кода, в
котором используется статическая переменная _someSharedLock:
lock(_someSharedLock) { /* здесь выполняются важные операции */ }
Теперь рассмотрим, что происходит, если во время блокировки происходит
внезапное прерывание потока. Вполне возможно, что прерванный поток редактировал
совместно используемое состояние, в таком случае велика вероятность того, что
теперь это состояние стало противоречивым. Более того, с уничтожением этого
потока блокировка осиротела, и теперь из-за преждевременного прерывания снять ее
невозможно. Велика вероятность взаимной блокировки других потоков, поскольку
блокировка _someSharedLock не может быть снята. Наилучшее решение с точки зрения
надежности – отправить на свалку весь домен приложения, в которой выполнялся
этот поток.
Чтобы обеспечить хостам CLR такой вариант, управляемый код может объявлять,
когда он собирается войти или покинуть критическую область, область, в которой,
возможно, хост захочет уничтожить весь домен приложения, если что-то пойдет не
так. Это можно осуществить с помощью новых статических методов
BeginCriticalRegion (начало критической области) и EndCriticalRegion (конец
критической области) класса Thread (поток). Если поток завершается в критической
области, хосты получают уведомление и могут обрабатывать сложившуюся ситуацию по
своему усмотрению. (Хосты, принимающие участие в управляемых распределениях
памяти, получают предупреждение также, если запросы памяти осуществляются из
критических областей; это позволяет хостам расставить приоритеты этих запросов
таким образом, чтобы минимизировать вероятность сбоя в критических областях.)
SQL Server использует это в своей политике эскалации сбоя как показано на
рисунке ниже.
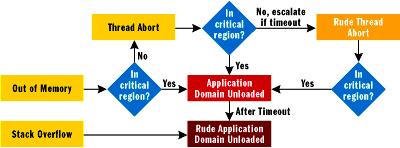
Пример политики эскалации хоста Если аварийное прерывание потока происходит в критической области, блокировка
удерживается, код, скорее всего, осуществлял редактирование совместно
используемого состояния, соответственно, это действие перерастает в выгрузку
домена приложения.
Ранее в своем примере я использовал ключевое слово C# lock как пример
использования критических областей. Однако, на самом деле, это не очень хороший
пример. Ключевое слово C# lock (SyncLock в Visual Basic) использует класс
Monitor, в который эта система уведомлений уже встроена. Остальные механизмы
блокировки не такие простые, как Monitor.
Рассмотрим события с автоматическим сбросом. Что значит для потока получить
«запрос» на событие с автоматическим сбросом? Не много. По существу то, что
среде выполнения требуется помощь разработчика, для того чтобы знать, когда код
выполняется в критической области. То есть необходимо применять
Thread.BeginCriticalRegion и Thread.EndCriticalRegion всегда, когда код
использует EventWaitHandle (от которого наследуются ManualResetEvent и
AutoResetEvent в .NET Framework 2.0), Семафор (Semaphore), взаимоблокировку,
специальный механизм блокировки или любой другой неуправляемый механизм
блокировки, доступ к которому вы осуществляете через P/Invoke.
FailFast и MemoryGates
CER и критические области позволяют среде выполнения и хосту CLR сделать ваш
код более надежным. Однако иногда происходит что-то настолько плохое, что
хочется взять все в свои руки и побыстрее уничтожить приложение, чтобы не
случилось еще что-то более страшное. В такой ситуации необходим метод,
позволяющий быстро завершить процесс приложения. Знакомьтесь, FailFast.
System.Environment.FailFast – это простой метод, выполняющий три вещи.
Во-первых, он записывает событие в регистрационный журнал приложения Windows,
указывая, что произошла фатальная ошибка. Это сообщение включает специальную
информацию, поставляемую в FailFast как его единственный строковый параметр.
Во-вторых, FailFast инициирует генерацию и пересылку в службу Microsoft Windows
Error Reporting (WER) отчета Watson об ошибках и мини-дампа. Потом с помощью
сервисов Windows Quality Online Services (winqual.microsoft.com
(http://winqual.microsoft.com/)) можно получить доступ к данным
WER по этому приложению и проанализировать их, чтобы найти причину проблемы. И,
наконец, FailFast уничтожает процесс.
FailFast хорош для обработки ситуаций, сложившихся в результате того, что
что-то пошло не так. А если для предупреждения сбоев проводить предварительный
контроль? Запрос памяти – это проверка наличия достаточного количества ресурсов
перед инициацией процесса, требующего большого объема памяти. В случае
отрицательного результата процесс не запускается, тем самым сокращается
возможность сбоя приложения, обусловленного недостатком ресурсов, во время
выполнения.
Запросы памяти реализованы в .NET Framework 2.0 посредством класса
System.Runtime.MemoryFailPoint. Чтобы использовать запрос памяти, создается
экземпляр MemoryFailPoint, в его конструктор передается число мегабайт памяти,
которые предполагает использовать будущая операция. Если объем доступной памяти
меньше, формируется исключение InsufficientMemoryException (недостаточно памяти)
(производный от OutOfMemoryException). Это может быть очень полезным, поскольку
исключения формируются перед началом процесса, а не во время, таким образом
устраняя зависимость от отменяющего изменения кода в некоторых сценариях. Обычно
MemoryFailPoint используется следующим образом:
using(new MemoryFailPoint(10)) //операции понадобится 10 MB памяти
{
... // осуществляется операция
}
В текущей реализации MemoryFailPoint система проверяет наличие указанного
количества памяти, но эта память не резервируется. Существует возможность того,
что появится другой поток или процесс и потребует эти ресурсы. Даже несмотря на
это, такие запросы памяти успешно используются уже в течение многих лет и
по-прежнему полезны для предоставления предопределенных контрольных точек
потребления ресурсов.
Заключение
Задача написать надежный код, учитывающий все возможные сбои, может привести
в уныние. Хорошая новость: если вы создаете не оболочку и не библиотеку для
использования в хостах CLR, которым необходимо обеспечить продолжительную
работоспособность, скорее всего, вам не придется думать обо всем этом слишком
часто. Тех, кто все же занимается именно этим, должно порадовать то, что .NET
Framework 2.0 предоставляет полезный набор инструментальных средств, облегчающих
эту задачу. Понимая принципы работы и использования этих систем, можно написать
управляемый код, настолько же надежный, как и аккуратно написанный неуправляемый
код.
Об авторе
Стивен Тауб (Stephen Toub) – технический редактор журнала
«MSDN Magazine», в котором также ведет колонку «Вопросы .NET».
Необработанные исключения
В .NET Framework 1.x лишь иногда необработанные исключения приводят к
прерыванию процесса, конкретное поведение зависит от типа потока, в котором
сформировалось исключение, и также от типа исключения. Необработанные исключения
потоков из пула потоков, потока финализатора и потоков, созданных с помощью
Thread.Start – все они поддерживаются средой выполнения. Потоки из пула потоков
просто возвращаются в пул потоков. Поток финализатора «проглатывает» исключение.
Потоки, созданные Thread.Start, завершаются постепенно. Необрабатываемые
исключения основного потока приложения приводят к завершению процесса. И потоки,
созданные явно функцией CreateThread (создать поток) Win32®, имеют собственный
набор правил.
Игнорирование необработанных исключений приводит к различным проблемам
надежности. Ошибки, которые в противном случае привели бы систему к краху – при
быстром вскрытии проблемы и, обычно, предоставлении важной отладочной
информации, например, стека вызовов в момент возникновения исключения – вместо
этого зачастую приводили к деградации производительности системы и, в конце
концов, к зависаниям и блокировкам. В результате команда CLR приняла решение о
несоответствии такой политики необработанных исключений, и в .NET Framework 2.0
она была заменена новой, которая облегчила разработчикам задачу по отслеживанию
подобных проблем.
В .NET Framework 2.0 все необработанные исключения приводят к прерыванию
процесса. Единственное исключение из этого правила – исключения, используемые
CLR для управления потоками, включая ThreadAbortException и
AppDomainUnloadedException. Это является переломным изменением, одним из
немногих, введенных в новой версии .NET Framework. По существу, есть два способа
отменить это поведение. Первый – для установления традиционного поведения можно
использовать конфигурационный файл:
<system>
<runtime><legacyUnhandledExceptionPolicy enabled="1"/></runtime>
</system>
Второй – приложение, являющееся хостом для CLR, может использовать метод
ICLRPolicyManager::SetUnhandledExceptionPolicy, чтобы сообщить CLR об
использовании политики необработанных исключений. Задание значения
eRuntimeDeterminedPolicy (политика, определяемая средой выполнения) указывает
среде выполнения использовать применяемую по умолчанию политику, которая состоит
в прерывании процессов при возникновении любых необрабатываемых исключений. В
качестве альтернативы, eHostDeterminedPolicy (политика, определяемая хостом)
может использоваться для указания CLR вернуться к поведения .NET Framework 1.x,
когда большинство исключений не трактуются как фатальные для процесса. В этом
случае хост может подписаться на необходимые связанные с исключениями события
соответствующего AppDomain и, таким образом, может реализовывать собственную
политику необработанных исключений.
Управляемые отладчики
Написать устойчивый к сбоям код непросто. Чтобы помочь в этом, .NET Framework
2.0 предоставляет Управляемые отладчики (Managed Debug Assistants – MDA) для
поиска проблем в коде во время выполнения. Если вы хорошо знакомы с Customer
Debug Probes (CDP), появившимися как отдельная часть в .NET Framework 1.x,
можете рассматривать MDA как их более зрелую версию. MDA – это тесты, встроенные
в .NET Framework, которые в активном состоянии проверяют наличие определенных
условий и предупреждают пользователя в случае их обнаружения. .NET Framework
предоставляет четыре MDA, касающихся CER. Эти MDA могут помочь выявить код,
связанный с CER, поведение которого не соответствует вашим ожиданиям. Вот
краткая справка по новым MDA для CER .NET Framework 2.0:
IllegalPrepareConstrainedRegions предупреждает о
неправильном размещении вызова RuntimeHelpers.PrepareConstrainedRegions. На
уровне MSIL вызов PrepareConstrainedRegions должен быть инструкцией перед
началом блока try. Если этот вызов обнаруживается в любом другом месте, появится
этот MDA.
InvalidCERCall формируется, если в схеме вызываемых функций
CER присутствует вызов метода со слабым контрактом надежности. Сюда относятся
все методы, не имеющие явно описанного контракта надежности или с контрактом,
определяющим, что домен приложения или состояние процесса может быть повреждено
в случае возникновения асинхронного исключения.
VirtualCERCall предупреждает о том, что схема вызываемых
функций CER использует виртуальную цель, например, вызов виртуального метода или
вызов через интерфейс. Это напоминает о необходимости проверки правильности
использования RuntimeHelpers.PrepareMethod для подготовки методов, которые могут
быть фактической целью этого вызова.
OpenGenericCERCall формируется в случае применения в схеме
вызываемых функций CER шаблонного типа с, по крайней мере, одним параметром
ссылочного типа. Машинный код, генерируемый JIT-компилятором для ссылочных
типов, используется совместно. Однако методы с переменными шаблонного типа плохо
распределяют ресурсы во время первого выполнения метода (эти ресурсы называют
элементами словаря шаблона). PrepareMethod может использоваться как обходной
прием в данном сценарии, так же как и с виртуальными и интерфейсными
методами.
MDA очень полезны для раннего выявления этого типа проблем. Конечно, такой
статический анализ с применением правил FxCop мог бы проводиться перед
выполнением кода. К сожалению, версия FxCop для Visual Studio® 2005 не включает
этих правил (создание правил FxCop будет хорошим домашним заданием). Более
подробную информацию по MDA, включая то, как их активировать, ищите в
документации .NET Framework.
Никакая часть настоящей статьи не может быть воспроизведена или
передана в какой бы то ни было форме и какими бы то ни было средствами, будь то
электронные или механические, если на то нет письменного разрешения владельцев
авторских прав.
Материал, изложенный в данной статье, многократно
проверен. Но, поскольку вероятность технических ошибок все равно существует,
сообщество не может гарантировать абсолютную точность и правильность приводимых
сведений. В связи с этим сообщество не несет ответственности за возможные
ошибки, связанные с использованием статьи.
|
|
| |
|
|
|
|